






Organic traffic is critical for any online business. It is a direct route for growing your website. There are studies that have shown that about 53% of the incoming traffic to your website can be attributed to organic search alone.
However, the basic prerequisite for inviting organic traffic to your website is that it should appear in Google search results.
You can get your site indexed by search engines like Google and Bing. There are two ways to do so. You can either sit back while waiting for the magic to happen. Or work to improve your conversion rate and promote valuable content.
This article takes a deep dive into indexing and crawling, and how you can get your website Google indexed.
What is indexing and crawling?
Indexing is when a search engine processes and stores information found during crawling in a huge database of content known as an index. As soon as a page gets listed on an index, it starts computing with other listed pages to show results for relevant search queries.
Crawling takes place before indexing. It concerns search engine bots scouring the internet for content and discovering publicly available pages. Search engines like Google send crawlers, a.k.a. little bits of computer code, to crawl the web to find new information to keep themselves updated.
This new information can be:
- An entirely new page on an existing website
- New content on an existing website
- An entirely new website
Crawlers need to find out what the new content is about when they discover new content. The search engine then indexes the content accordingly.
Your job is to be found by these crawlers and get indexed on Google and other search engines, and for that, you need to have an efficient crawl rate.
Why is it important for Google to index your website?
Google needs to index your website to list and rank it in search results and improve user experience. Google spiders crawl the web to find pages and process information from the pages worthy of indexing and crawling and ranking.
These spiders or crawlers add all the new information and data to the Google Index. Pages or data that are eligible to be added to Google Index consist of useful content and must not be associated with keyword stuffing and other shady activities like attaching links from unreputable sources.
Whenever you add, edit, or change info on your site or page, spiders process the content and location of the newly added content on the page. Besides the text, the spiders consider meta titles, meta tags, meta descriptions, and alt text for images.
The spiders add this new information to the index. Regular indexing and crawling helps to improve your ranking in the SERPs. If the crawlers cannot find your page or website, they won’t appear in the search results.
This is how indexing and crawling works. Suppose a user searches for a query using keywords relevant to your site and pages. What happens next?
Google’s algorithm starts working to decide where to rank your page against all the relevant search results related to the keyword search.
It is crucial that every update you make on your website is indexed properly and visible to users searching for information as well as to Google spiders. This is where continuous indexing and crawling helps. Google spiders keep crawling your website to find new content at all times.
Your site performance in search results improves when your site gets indexed frequently. Bing, Yahoo, and other search engines follow a similar process to find, analyze, and index information to improve user experience.
How to make your website part of Google Index
If Google doesn’t index your website or page, fret not. Here’s a step-by-step guide to getting your site/page indexed by Google:
- Open Google Search Console on your device.
- Go to the URL inspection tool.
- Copy and paste the URL you want to index in the search bar.
- Let Google check the URL.
- Click on the ‘request indexing’ button.
This method is an effective way of telling a search engine that you have published a new post or added a new page. You request the search engine to look into your site/blog by directly sharing the URL link.
This practice may be great for telling Google about the presence of new pages, but what about the old pages still waiting to be indexed? If you have some old pages lying around unindexed, you need to follow a different procedure to get the problem diagnosed and your page/site/blog indexed by Google.
Here are some great ways you can choose from to get your site issues fixed and improved for Google to index your site easily:
Robots.txt crawl blocks removed
Google may not be indexing your website for several reasons. One such reason may be due to a crawl block called a robots.txt file. If you think your site or page also faces this kind of crawl block, go to yourdomain.com/robots/txt.
Try to search for any of these code snippets:
| 1 | User-agent: Googlebot |
| 2 | Disallow: / |
| 1 | User-agent: * |
| 2 | Disallow: / |
These code snippets work as a command telling Google not to crawl select pages on your site. There is a simple fix to get rid of this issue – remove the code snippet. But there are chances that the crawl block still exists in robots.txt, which is preventing Google from indexing and crawling any page at all.
To detect such crawl blocks, go to Google Search Console. Paste the URL in the URL inspection tool. Click on the coverage block to read further details and try to find any “Crawl allowed? No: blocked by robots.txt” errors.
Double-check your robots.txt file for any “disallow” rules relating to your page or subsection if you find any such issues.
Remove any rogue “noindex” tags
There will be instances when you want to keep some pages private. Google can be told not to index your page in that case. You can do this using two methods:
Step 1: meta tag
Google won’t index any pages having the following meta tags in their <head> section. This is a meta robots tag. It tells search engines if they should index the page or not. The main part of the meta tag is the “noindex” value. If you find that value in the code of any page, that page won’t be indexed by Google.
| 1 | <meta name=“robots” content=“noindex”> |
| 1 | <meta name=“googlebot” content=“noindex”> |
Run a crawl on a Site Audit tool like Ahrefs to discover pages with the “noindex” meta tag. Next, open the indexability report and look for “noindex page” warnings. Click to see the pages affected by the meta tag. Remove the “noindex” meta tag from any pages you consider eligible for Google Indexing.
Step 2: X-Robots-Tag
Besides the “noindex” meta tag, the X-Robots-Tag HTTP response header is what asks the crawlers not to index the page. Implement this kind of response header using a server-side scripting language like PHP or change your server configuration in your .htaccess file.
Conduct a crawl test using a Site Audit tool to check for such issues across your site. Use the “Robots information in HTTP header” filter in the Page Explorer:
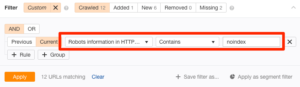
You can ask your developer to specifically exclude pages you want to get indexed from returning to this header.
Add the page to your sitemap
Google can find pages on your website even if they are not included in your sitemap. But it is always a good practice to include all your pages in your sitemap. Sitemap presents the structure of your website to Google and tells it which pages are important. Site maps are also crucial for directing Google on the number of times the pages on your site should be recrawled.
Use the URL inspection tool in the Search Console to see whether the page is part of your sitemap. If you see the error message “URL is not on Google” and “Sitemap: N/A,” the page is not in your sitemap or indexed by Google.
Another option to use to discover whether a page is in the sitemap is to head to your sitemap URL and search for the page. The sitemap URL is usually yourdomain.com/sitemap.xml. You can also run a Site Audit to find all the pages not in your sitemap that you want to be crawled and indexed by Google. To do so, go to the Page Explorer and use filters such as “is indexable – yes”, “is in sitemap – No”, “previous”, “current”, etc.
Add the pages you see as results in your sitemap and inform Google about them by pinning the URL: http://www.google.com/ping?sitemap=http://yourwebsite.com/sitemap_url.xml
Remove any rogue canonical tags
<link rel=”canonical” href=”/page.html/”>
A canonical tag looks something like the code above and informs Google about the preferred version of a page. Most pages do not carry self-referencing canonical tags. Such canonical tags inform Google that the page in its current version is the most preferred and the only version, and that you want this version of the page to be indexed.
But there are chances that your page might be carrying a rogue canonical tag. Such tags inform Google of a preferred version that doesn’t exist in the first place. And if the preferred version doesn’t exist at all, how will the website be Google indexed?
Use Google’s inspection tool to check for canonical tags and if the canonical tag points to another version, the tool will display a warning: “Alternate page with canonical tags”. If no other version exists for the page or if you want that particular page to be indexed, simply remove the canonical tag.
Ahref’s Site Audit tool can also help you quickly discover any rogue canonical tags across your site. Go to Page Explorer and look for pages in your sitemap that have non-self-referencing canonical tags. If the filter pulls up a result, it is likely that the pages have rogue canonical and must be fixed immediately.
Ensure that the page isn’t orphan
A page is called an orphan page when it has no internal links pointing toward it. Google spiders crawl the web using internal links, and if a page has no internal links, Google cannot discover the page through crawling, and visitors on your website won’t be able to discover the page either.
Use Ahrefs’ Site Audit to crawl your site and discover orphan pages, if any. You can do so by checking the Links Report for any “Orphan Page (has no internal links)” errors. The report shows all the indexable pages present in your sitemap having no internal links pointing toward them.
If you aren’t confident that the indexable pages are in your sitemap, ensure the following steps are followed:
- Download a full list of pages on your site using your CMS
- Use a Site Audit tool to crawl your website
- Now cross-check both the lists to find abandoned or orphan pages.
You can fix the issue of orphan pages using two methods:
- Delete and remove the page from your sitemap if it is not important.
- Incorporate the page into your site’s internal link structure if the page is important.
Resolve “nofollow” internal links
Links that have a “nofollow” tag are called nofollow links. These links don’t allow any PageRank transfer to the destination URL. Google is also incapable of crawling nofollow links as it causes Google to drop the target links from Google’s overall graph of the web. But if other sites link to that page without using the “nofollow” tag or if the specific URLs are submitted to Google for indexing, the target pages may appear in Google Index.
To make sure all your website is Google indexed, all internal links to indexable pages should be followed. You can go about doing this by following these quick steps:
- Use a Site Audit tool to crawl your website
- Check the link report for indexable pages with ‘Page has nofollow incoming internal links only” errors
- If you want Google to index your page, remove the “nofollow” tag from these internal links
- Lastly, simply delete the page or “noindex” it
Include powerful internal links
Google discovers pages on your website by crawling via the internal links. Without such links, it will be unable to find or index the pages. There are two ways to avoid this. Either add some internal links to other crawlable and indexed pages or link them to more ‘powerful’ pages for Google to index the page quickly.
Google will likely recrawl these pages faster than less important pages. Do so by following these steps:
- Visit a Site Explorer like Ahrefs’, enter your domain, and open the Best by Links report.
- Go through the list of all the pages on your website sorted by ULR Rating (UR).
- Look for relevant pages to be added as internal links to the page in question.
Next time Google recrawls, it will identify and follow that link.
Ensure the page is valuable and unique
Since Google lays great importance on user experience, it is less likely to index low-quality pages. If no technical issues are bothering your site, then the lack of quality content may be why Google does not index your pages frequently.
If a relook at your page tells you that your content needs redoing to be considered more valuable, consider revamping that web page. You can find more potentially low-quality pages using URL Profiler and Site Audit Tool like the one from Ahrefs. Follow these steps to identify more of these low-quality pages:
- Go to Page Explorer in Ahrefs Site Audit and use custom settings like ‘is indexable page – yes,’ ‘no. of content words – 300,’ and ‘organic traffic – 0.’
- The search results will show you all your ‘thin’ indexable pages with zero organic traffic.
- Export the report and run a Google Indexation check after pasting all URLs into URL profiler.
- Check the non-indexed pages for quality issues and improve where necessary.
- Request Google Search Console for reindexing the page.
Use the Duplicate Content Report to fix the duplicate and near-duplicate pages on your site.
Optimize crawl budget by removing low-quality pages
If your site is having many low-quality pages, your crawl budget will be reduced and the good pages will miss the chance of getting discovered. Google states that “crawl budget […] is not something most publishers have to worry about,” and that “if a site has fewer than a few thousand URLs, most of the time it will be crawled efficiently.”
But removing low-quality pages from your website is never a bad thing. While on one site, it would help to improve the health of your website and the quality of content posted, it can also positively impact the crawl budget.
A content audit template can help you find potentially low-quality and irrelevant pages worth deleting on your website.
Create high-quality backlinks
Any website will backlink to a page on your site if it holds some value. For the same reason, Google considers backlinks important and pages with backlinks as high quality.
Though backlinking isn’t the only factor Google uses to index your pages, it is likely to crawl and recrawl those pages more often and faster. This leads to indexing and crawling your pages faster. There are multiple resources and guides you can use to build high-quality backlinks on the blog.
Indexing and ranking are two different things
Indexing isn’t the same as ranking your website. Even if your site is indexed, it doesn’t mean Google will rank your website high or there will be more incoming traffic to your website.
Indexing allows your site to become a part of Google’s database and increases your chances of ranking. Meanwhile, ranking is more a factor of SEO, optimizing your site for particular queries to rank on search engines.
SEO involves discovering what your customers are looking for, building content around those topics to attract them, optimizing that content for keywords, building backlinks, and regularly republishing to rank consistently on search engines.
Conclusion
Either your site is facing technical issues, or your content isn’t worthy of being indexed on Google. There can be either of the two issues, or both issues preventing your site from getting indexed on Google.
While low-content quality does hamper your indexing prospects, most of the time, technical issues hamper the crawling and indexing process. Moreover, technical issues can be one of the reasons for the auto-generation of low-quality content on your website.
Hopefully, you are now aware of the several ways in which to fix the technical issues and get your page/site to become a part of Google Index. However, indexing and crawling isn’t a guarantee for ranking on search engines. The ranking is motivated by your SEO efforts, follows indexing, and precedes the flow of organic traffic to your website.
![]()